Continual Learning Is the Real Frontier
The interesting question for agents is no longer whether they can use tools, follow workflows, or pass a benchmark. It is whether they can learn continuously from experience.
Once deployed, an agent does not operate in a fixed benchmark. It sees diverse users, tools, memories, workflows, policies, and data. The agent that worked yesterday can become brittle tomorrow because the environment around it keeps changing.
A self-improving agent should not treat failures and near-misses as isolated bugs. It should treat them as training signal. The goal is to build a system that gets better over time while preserving what already works.
But here is the hard part: an agent that improves on today’s failure while breaking yesterday’s capability is not really learning. It is drifting.
A credible continual learning system makes every improvement verifiable: tested before it is trusted, and regression-aware as it optimizes, not after.
If we get it right, agents become more capable through experience in the same practical sense that strong engineering teams do: every incident becomes a test making the next version harder to break.
This also changes the agent maintenance problem. As organizations deploy more agents, the real bottleneck may not be building the first agent; it may be maintaining the hundredth. If every agent requires manual prompt tuning, ad hoc eval updates, and constant human triage, the maintenance overhead can grow faster than the agents themselves.
Over the past two years, this became my main obsession: what would a reliable learning system for AI agents actually look like?
Several recent efforts have started to answer pieces of this question:
- Prompt and harness optimizers (e.g., GEPA) treat language as an optimization surface: reflect on trajectories, mutate prompts or textual components, and select improvements against a benchmark.
- Memory and skill consolidation (e.g., dreaming-style review) compresses past sessions and writes lessons back into memory so future behavior improves.
- Coding agents (e.g., Codex, Claude Code) can modify agent code and harnesses directly.
- Trace-to-fix systems (e.g., LangSmith Engine, HALO, Meta-Harness) go one level higher: they analyze production traces, surface common failure modes, and propose or apply changes, from suggested evals to harness-level repairs, fed through a coding agent.
Each of these solves a real piece of the puzzle. The open problem is connecting them. A failure rarely maps to one layer. The right fix might combine a prompt change, a tool fix, and a model update. Whatever the fix, it has to be verified to generalize without regressing prior capabilities, cheaply enough to run continuously. No single tool owns that loop.
The missing abstraction is the lifelong learning engine: the outer loop that converts experience into durable improvement in a verifiable, generalizable, and efficient way.
As I studied different approaches to agent learning and self-improvement, I kept coming back to four principles for a robust continual learning framework:
- Replayable — failures and feedback become learning environments where improvements can be tested and verified.
- Lifelong — new improvements are optimized without forgetting prior capabilities.
- Holistic — feedback is routed to the right layers of the agent stack.
- Efficient — learning remains practical in tokens, time, and cost.
Without replayability, improvements are hard to trust. Without lifelong learning, improvements create regressions somewhere else. Without holistic repair, prompts become landfills. Without efficiency, learning never becomes operational.
The rest of this post explains why these four properties matter, where current systems fall short, and how we might close those gaps.
1. Replayable: Turn Experience Into Learning Environments
If an agent fails on a log, the learning engine should not jump directly from bad log → coding agent → change. That produces an update, but it does not necessarily produce learning.
A failure log is not the environment. It is one sample from the environment.
The real object we want is a learning environment: a replayable setting that captures the failure mode and defines what success means.
Not:
Here is one bad run. Please improve the agent.But:
Here is a replayable learning environment that captures the failure.
Can the new agent handle it reliably?This environment may include real tools, mocked tools, synthetic users, perturbations, grading logic, or domain-specific checks. Building it is technically challenging because the learning engine is, in effect, trying to infer a distribution from one or a few samples. Doing this well requires strong inductive biases about which variations matter and what success should mean.
Ideally, learning environments should not only come from production logs, they should also be creatable during development through prompting, so teams can synthesize realistic scenarios, study agent behavior, and fix weaknesses before they show up in production.
Many decisions have to be made carefully. Which tools should be real, and which should be mocked? If a tool is mocked, how should the mock be conditioned on the observed failure? What synthetic users or personas should be created? What grading logic should define success inside the environment?
These questions are technically challenging, but the payoff is simple: the improvement becomes testable.
Without replayability, agent improvement is mostly vibes. With replayability, a failure becomes an actionable lesson.
2. Lifelong: Improve Without Forgetting
Agents do not live in one environment. They live across many: users, workflows, datasets, tools, policies, memories, and product surfaces.
Suppose the agent already performs well on environments:
E_1, E_2, ..., E_kThen a new failure appears from environment:
E_{k+1}A naive loop improves performance on E_{k+1}, then runs a regression check afterward to see if anything broke. This is post-hoc: the test happens after the change, as a gate rather than a guide.
The improvement and the regression analysis should be part of the same optimization problem. Otherwise, the system drifts:
- improve behavior A → break behavior B
- recover behavior B → break workflow C
- repair workflow C → prompt becomes unreadable
- rewrite prompt → behavior A regresses
This is not hypothetical. It is the daily life of agent engineering.
A lifelong learning system must optimize for both sides:
improve on the new environment
s.t. preserving performance on prior environmentsThis is the agent version of avoiding catastrophic forgetting. The learning engine needs online generalization control: it must remember not just lessons, but the tested environments that represent accumulated competence. It should also use them intelligently. Having seen k environments, it should not blindly replay all k every time a new issue appears because that does not scale with the agent’s experience.
3. Holistic: Backpropagate Feedback to the Right Layer
In neural network training, feedback is backpropagated to weights. In agents, there is no single place where learning must go. The feedback can be backpropagated to different layers:
- Model layer → model choice, routing, fine-tuning or weights
- Harness layer → prompts, tools, skills, workflows, policies, code
- Memory layer → memory content, retrieval, consolidation, update rules
So the choice is rarely “edit the prompt.” Sometimes the prompt is wrong. Sometimes the agent needs a new tool, or the tool exists but its output needs normalization. Sometimes memory retrieves stale facts, the workflow decomposition is off, or one node just needs a stronger model. And often the real fix is a combination: a prompt change, a tool enhancement, and a small workflow adjustment, applied together. The edit locations are not mutually exclusive, which is what makes holistic optimization hard.
If the optimizer can only edit prompts, every failure becomes a prompt failure. That is how prompts become landfills. They accumulate warnings, exceptions, examples, counterexamples, tool-use reminders, and haunted little sentences like:
IMPORTANT: Avoid repeating this failure mode.A lifelong learning engine should ask:
Which locus should this feedback be backpropagated to?The learning system needs a holistic view of the agent stack and enough root-cause analysis to place the repair where it belongs. The goal is not maximum change. The goal is the smallest durable change at the right layers.
4. Efficient: Spend Tokens Like Money
A lifelong learning engine that needs billions of tokens to improve one issue is not a learning engine. It is a research demo with a cloud bill. Efficiency matters because learning must run often.
Production agents generate a continuous stream of traces, failures, near-misses, and feedback. If each improvement cycle is too slow, too expensive, or too manual, the loop stops being operational.
Different ways of generating an update have very different costs. Ingesting a fact into memory is nearly free. Distilling a skill from a successful trajectory is cheap. Mutating prompts and re-evaluating them in a search loop is mid-cost. Fine-tuning weights, even with LoRA, is expensive.
The engine should spend tokens efficiently. That means narrowing the repair space through root-cause analysis. Reusing prior environments intelligently. Avoiding exhaustive retesting when targeted regression control is enough. Avoiding prompt bloat when a tool wrapper or workflow change is cleaner. Avoiding harness rewrites when a small memory policy fix solves the issue.
Efficiency is not separate from the other principles. Replayability makes evaluation targeted. Lifelong memory avoids rediscovering the same failures. Holistic repair avoids expensive prompt-only fixes. Together, they make continuous learning practical.
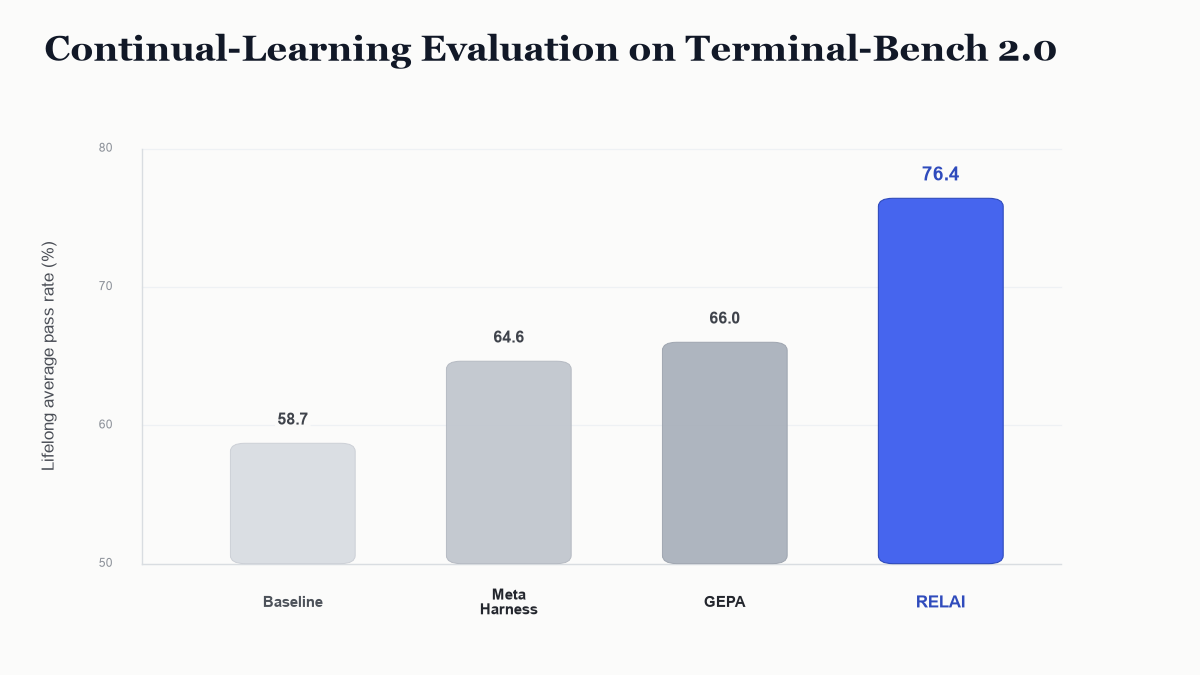
What We Are Building at RELAI
At RELAI, we are building a continual learning engine for AI agents around these principles. The goal is not to replace evals, traces, memory systems, or coding agents. It is to connect them into a verifiable continual learning engine: failures become replayable learning environments; improvements are evaluated against both new and prior behavior; feedback is routed to the right layers of the agent stack; and the loop remains efficient enough to run continuously.
We believe the next generation of agents will not just be prompted better. They will learn from experience, the way every great system eventually must.
If these are the problems that keep you up at night, reach out. We would love to chat.